Machine learning in de audit: voorspellen van klantverloop
Het doel van machine learning is om voorspellingen te maken aan de hand van data. Binnen dit veld worden doorgaans drie hoofdtoepassingen onderscheiden: classificatie, regressie en clusteren. Deze column gaat over classificatie.
Koen Derks
Classificatie is een vorm van machine learning die streeft naar het voorspellen van een categorische (dat wil zeggen niet-numerieke) variabele op basis van diverse kenmerken. Classificatie kent talloze praktische toepassingen en wordt tegenwoordig ook gebruikt in de audit. Zo kun je deze techniek bijvoorbeeld gebruiken om de continuïteit van een bedrijf te voorspellen als zorgelijk of niet, gebaseerd op verschillende financiële kengetallen.
Op dezelfde wijze kun je het frauderisico van declaraties voorspellen als hoog of laag op basis van bijvoorbeeld de doorlooptijd en het bedrag dat wordt gedeclareerd. Deze voorspellingen zijn mogelijk dankzij algoritmes die zijn getraind op data. Het trainen van dit soort algoritmes is echter niet eenvoudig en vereist vaak programmeerkennis. Dat is jammer, want dit vormt een obstakel voor het breder gebruik van deze innovatieve methoden.
In deze column demonstreer ik hoe je met het gratis open-source statistiekprogramma JASP (JASP Team, 2024; www.jasp-stats.org) zonder enige programmeerkennis een machine learning algoritme voor classificatie kan trainen en deze daarna kan toepassen in de context van een audit. Als voorbeeld behandel ik een situatie waarin je als auditor het klantverloop bij een telecomprovider wil voorspellen als onderdeel van de risicobeoordelingsactiviteiten.
Klantverloop
Klantverloop is het fenomeen waarbij klanten stoppen met het gebruik van de diensten van een bedrijf. Het voorspellen van klantverloop in het komende jaar kan relevant zijn in de risicobeoordingsfase van een audit, aangezien een volatiel klantenbestand een risico kan zijn voor de continuïteit van het bedrijf.
In dit voorbeeld gebruik ik een voor deze column licht bewerkte versie van de algemeen toegankelijke Telco Customer Churn-dataset*. Belangrijk om op te merken is dat het hier om voorbeeldgegevens gaat. In de praktijk kun je beter historische gegevens uit de database van de telecomprovider gebruiken.
De voorbeeldgegevens bevatten voor 3.738 klanten kenmerken zoals demografische informatie, details van het telefoon- en internetcontract en of de klant het contract bij de telecomprovider heeft opgezegd**. Naast deze voorbeeldgegevens is ook het huidige klantenbestand van de telecomprovider bestaande uit tweeduizend klanten beschikbaar***. Voor deze klanten is nog onbekend of zij het komende jaar het contract gaan opzeggen.
Theorie classificatie
Voordat ik laat zien hoe je met behulp van JASP een classificatiealgoritme kunt trainen om het verwachte klantverloop te voorspellen, behandel ik eerst kort de theorie achter classificatie. Het uitgangspunt van een classificatiealgoritme is dat er een relatie bestaat tussen de klantkenmerken en het klantverloop. Als je deze relatie weet, kun je op basis van de klantkenmerken voorspellen of een klant in het komende jaar het contract zal opzeggen. Het is echter onbekend hoe de klantkenmerken zijn gerelateerd aan het klantverloop, dus deze relatie moet het algoritme leren uit historische gegevens.
Om de relatie te leren kun je het classificatiealgoritme een deel van de historische gegevens laten zien, bijvoorbeeld van 3.238 klanten. Dit heet de zogenaamde trainingsset. In dit voorbeeld bevat de trainingsset zowel de kenmerken als het verloop. Om vervolgens te evalueren of de geleerde relatie goed generaliseert naar klanten die het algoritme nog niet heeft gezien, kun je een zogenoemde testset, bestaande uit vijfhonderd klanten, apart houden tijdens de trainingsfase.
Zowel de trainingset als de testset moeten niet te veel uit balans zijn, zodat er ongeveer een gelijk aantal klanten die wel en niet hebben opgezegd aanwezig zijn. Dit is van belang om te voorkomen dat het algoritme een voorkeur heeft voor één van de twee klassen simpelweg omdat deze vaker voorkomt in de trainingsset. In dit voorbeeld zijn de trainings- en testset gebalanceerd door de data van sommige klanten uit te sluiten, waardoor er een evenwichtige verdeling van klanten is die wel en niet hebben opgezegd. Zodra deze trainings- en testset beschikbaar zijn, kun je beginnen met het trainen van een classificatiealgoritme.
Trainen classificatiealgoritme
Het trainen van een classificatiealgoritme kun je doen in JASP door eerst JASP te downloaden van www.jasp-stats.org en te installeren. Na het inladen van de gegevens in JASP kun je de Machine Learning module inschakelen door op het '+'-symbool in de rechterbovenhoek te klikken en 'Machine Learning' te kiezen. Hierdoor verschijnt de module in het menu boven in het scherm. Door vervolgens op de module te klikken, kun je alle functies zien die de module biedt. Via het menu in de linkerbovenhoek (Preferences - Interface - Preferred language) kun je daarnaast instellen dat de interface en de resultaten in het Nederlands worden weergegeven.
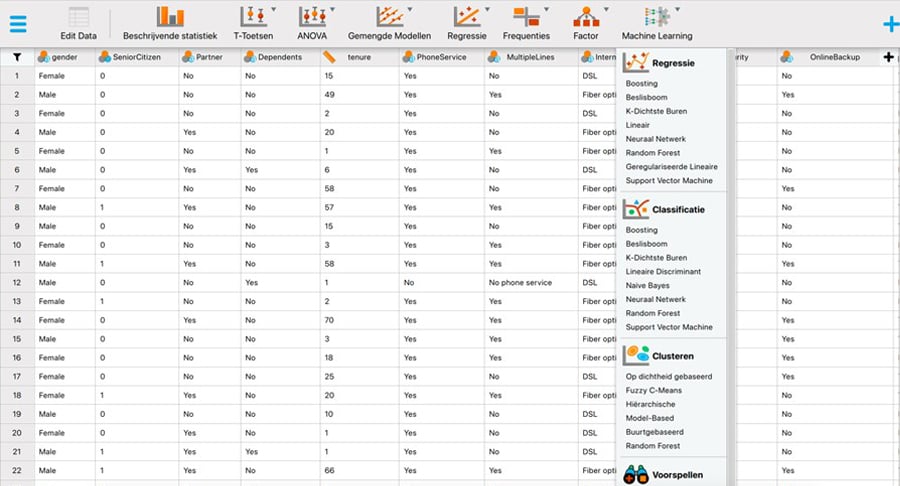
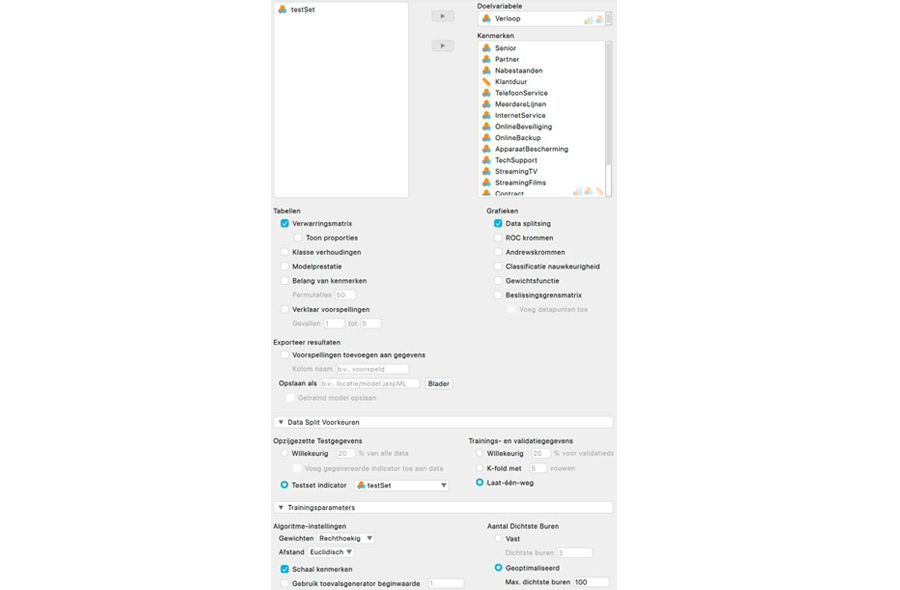
Zoals te zien is in de bovenstaande screenshot zijn er voor het leren van de relatie tussen de klantkenmerken en het klantverloop verschillende classificatiealgoritmes beschikbaar. In deze column kies ik voor een K-dichtste buren algoritme (James et al., 2023, pp. 183–188). Om dit algoritme in JASP te gebruiken, selecteer je in het Machine Learning menu de optie 'K-Dichtste Buren' onder 'Classificatie'. Vervolgens open je in de hieronder weergegeven interface de sectie 'Data Split Voorkeuren', selecteer je de optie 'Testset indicator' en wijs je deze de variabele testSet toe met behulp van het keuzemenu. Dit zorgt ervoor dat het algoritme de vooraf gespecificeerde 3.238 klanten gebruikt om het K-dichtste buren algoritme te trainen en de overige vijfhonderd klanten gebruikt om het algoritme te evalueren.
In dezelfde sectie klik je onder 'Trainings- en validatiegegevens' op 'Laat-één-weg' (James et al., 2023, pp. 204–206). Hiermee geef je aan dat er tijdens de trainingsfase elke keer één rij uit de trainingsset wordt gebruikt als validatieset, terwijl het algoritme wordt getraind op de rest van de trainingsset. Dit proces wordt herhaald voor elke rij in de trainingsset met als doel om het algoritme het optimale aantal dichstbijzijnde buren, K, te laten identificeren.
Daarna open je de sectie 'Trainingsparameters' en voer je onder het kopje 'Aantal Dichtste Buren' 100 in als het maximumaantal****. Vervolgens sleep je de variabele Verloop naar het vak voor de doelvariabele. Als laatste selecteer je alle overige variabelen behalve testSet en sleep je deze naar het vak voor de kenmerken.
Zodra alle gegevens zijn ingevoerd, begint JASP met het trainen van het classificatiealgoritme. De resulterende output is hieronder weergegeven. Uit de tabel en de figuur daaronder blijkt dat het trainen en optimaliseren van het K-dichtste buren algoritme resulteert in een K=67-dichtste buren-model. Daarnaast toont de output dat dit K=67-dichtste buren-model een nauwkeurigheid van 0,79 op de testset behaalt, wat betekent dat je voor 79 procent van de klanten in de testset correct kunt voorspellen of deze het contract bij de telecomprovider hebben opgezegd.

De onderstaande verwarringmatrix biedt meer inzicht in de prestaties van het algoritme door te tonen hoe de voorspellingen voor de klanten in de testset overeenkomen met de werkelijkheid. Uit de verwarringsmatrix blijkt dat het algoritme correct voorspelt dat 215 klanten het contract zouden opzeggen, en dat het ook correct voorspelt dat 180 klanten het contract niet zouden opzeggen. Dit leidt tot een nauwkeurigheid van het algoritme op de testset van (215 + 180) / 500 = 0,79, wat overeenkomt met 79 procent.

Voorspelling
Op basis van de trainingsset kun je een absolute voorspelling doen voor een klant in het huidige klantenbestand (die niet in de trainingsset of testset zit) in termen van 'Ja, deze klant zal het contract opzeggen' of 'Nee, deze klant zal het contract niet opzeggen'. Door echter een testset te gebruiken, kun je de mate van onzekerheid bepalen waarmee deze voorspelling wordt gedaan.
Voor een klant in het huidige klantenbestand kun je nu, op basis van de verwarringmatrix, een genuanceerde voorspelling doen zoals 'Ja, deze klant zal het contract komend jaar opzeggen met een kans van 75,4 procent', aangezien 215 / (215 + 70) = 0,754, of 'Nee, deze klant zal het contract komend jaar niet opzeggen met een kans van 83,7 procent', aangezien 180 / (180 + 35) = 0,837. Het is aan jou om te beoordelen of deze mate van zekerheid voldoende is om conclusies op te baseren.
Toepassen
Als je tevreden bent met de prestatie van het algoritme, is de volgende stap het toepassen van dit algoritme om voorspellingen te maken voor de tweeduizend klanten in het huidige klantenbestand van de telecomprovider. In JASP kun je dit doen door het getrainde algoritme op te slaan via de optie 'Getraind model opslaan'. Het huidige klantenbestand kun je daarna inladen in een nieuwe sessie.
Allereerst navigeer je naar de optie 'Voorspellen' in het machine learning-menu en laadt daar het opgeslagen model in. De kenmerken van de klanten in het huidige klantenbestand sleep je dan naar het daarvoor bestemde veld. Vervolgens klik je onder in de interface op 'Voorspellingen toevoegen aan gegevens'. Ten slotte kun je naar 'Beschrijvende statistiek' gaan om frequentietabellen van de voorspellingen te genereren.
Deze tabel, die hieronder is weergegeven, toont aan dat voor 120 van de tweeduizend huidige klanten, oftewel 6 procent van het huidige klantenbestand, is voorspeld dat ze het contract komend jaar zullen opzeggen. Je kunt deze voorspellingen verder verfijnen door de onzekerheid uit de testset in overweging te nemen, of door de onzekerheid in de individuele klantvoorspellingen te incorporeren. Voor het gemak wordt het verfijnen van de voorspellingen in deze column overgeslagen.

Acties
Op basis van het voorspelde klantverloop kun je acties ondernemen om de risico's voor de continuïteit in te schatten. Met 6 procent van de huidige klanten die naar verwachting het contract komend jaar zullen opzeggen, kan er bijvoorbeeld een aanzienlijk risico op inkomstenderving zijn, als dit niet wordt gecompenseerd met een vergelijkbaar percentage nieuwe klanten. Mocht dat inderdaad niet het geval zijn, dan kun je op basis van deze resultaten aanbevelen om preventieve maatregelen te nemen, zoals het verbeteren van de klantenservice, het aanbieden van loyaliteitsprogramma's of het herzien van de prijsstelling.
Daarnaast kun je een diepgaande analyse uitvoeren van de klanten die waarschijnlijk het contract zullen opzeggen om gemeenschappelijke kenmerken te identificeren. JASP kan namelijk de kenmerken identificeren die het meest bijdragen aan de voorspelling. Deze kenmerken kun je vervolgens als basis gebruiken voor je aanbevelingen. In dit geval zijn dat bijvoorbeeld de duur van de klantrelatie, het type contract (éénjarig, tweejarig of maandelijks opzegbaar), en het gebruik van technische ondersteuning door de klant. Deze informatie kan de telecomprovider vervolgens gebruiken om gerichte retentiestrategieën te ontwikkelen en zo het risico op klantverloop te verminderen.
Natuurlijk kun je deze workflow in JASP ook gebruiken om een classificatiealgoritme te trainen voor andere auditdoeleinden. Als je deze technieken zelf wil toepassen, dan kun je JASP gratis downloaden en installeren via www.jasp-stats.org.
Voetnoten
* De originele dataset is te vinden op https://www.kaggle.com/datasets/blastchar/telco-customer-churn.
** De gebruikte voorbeeldgegevens zijn te vinden op https://www.statisticalauditing.com/files/resources/data_churn_traintest.csv.
*** Deze data zijn te vinden op https://www.statisticalauditing.com/files/resources/data_churn_prediction.csv.
**** In dit voorbeeld wordt de trainingsfase gebruikt om de beste waarde voor 'K' te bepalen. Echter, in JASP heb je de mogelijkheid om zelf een waarde van 'K' in te voeren door onder 'Aantal Dichtste Buren' de optie 'Vast' te selecteren en de gewenste waarde van 'K' in te voeren in het bijbehorende veld. In dat geval is er geen sprake van een trainingsfase.
Referenties
- JASP Team. (2024). JASP (Versie 0.18.3) [Computer software].
- James, G., Witten, D., Hastie, T., Tibshirani, R., & Taylor, J. (2023). An Introduction to Statistical Learning with Applications in Python. Springer. https://hastie.su.domains/ISLP/ISLP_website.pdf.download.html
Gerelateerd

De steekproefomvang ontmaskerd - deel 5
In vorige columns hebben we verschillende manieren besproken om tot een steekproefomvang te kunnen komen. Deze column is de laatste van de serie waarin we verschillende...

De steekproefomvang ontmaskerd - deel 4
Een accountant die gebruikmaakt van software om een steekproefomvang te berekenen, moet zeker weten dat die software dat goed doet. Daarvoor moet je de rekenmethode...

Symposium: Machine Learning in de audit
Hoe is het momenteel gesteld met de toepassing van Machine Learning in de audit? Aankondiging van een symposium.

De steekproefomvang ontmaskerd - deel 3
Steekproefomvangen berekenen doen we meestal met rekenbladen in Excel of statistische software. Hoewel velen van ons statistiek hebben gehad, is het berekenen van...

De steekproefomvang ontmaskerd - deel 2
Deze tweede column in een serie van vijf bespreekt hoe je zelfstandig de juiste steekproefomvang kunt berekenen.